序
之前写了个爬学校各大网站新闻然后推送到邮箱的程序,上线了几个月,一直正常运行,还收获了一些用户
直到前几天突然发现.. 似乎很久没收到过邮件推送的教务处的更新了,莫非教务处改了网页,爬虫拿不到数据了?
手抖删库
ssh连到服务器里面,检查了下负责教务处的jwc.py, 发现运行返回值是None, 正常情况下是返回当前页面所有的新闻的标题和url, 每个新闻的具体内容,确认就是这里出问题了。
线上改代码还是不行的,虽然并没有几个人用我的服务,但是理智告诉我应该换个地方修,不要把数据库里面的数据搞坏了,看了下前不久的用户地址备份还在,坏了也可以修,所以没怎么在意
1
2
cd /tmp
git clone ~/scurss
复制到另一个地方去了,因为端口绑定问题,所以关掉了服务再来改,
1
docker-compsoe up
进去发现不对啊,咋个和scurss目录数据是一样的,那么干掉吧
1
docker-compose down -v
干干净净,但是看输出的log似乎不对啊..好像dorp掉了数据库,赶紧检查一下
凉了,真实版删库,还好没新增用户,备份还有用。
不要使用
docker-compose down -v, 除非你知道你在干什么 —孔壕
没事,还能恢复的,所以继续修教务处的bug
修bug
直接运行负责爬教务处的jwc.py, 返回值只有一堆混淆的js, 再看看浏览器打开的教务处,似乎source code不一样..
异步加载了吗?F12看一下,并没有..复制浏览器里面的命令到curl, 又可以正常打开,
1
$ curl 'http://jwc.scu.edu.cn/jwc/frontPage.action' -H 'DNT: 1' -H 'Accept-Encoding: gzip, deflate' -H 'Accept-Language: zh-CN,zh;q=0.9,en-US;q=0.8,en;q=0.7' -H 'Upgrade-Insecure-Requests: 1' -H 'User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.162 Safari/537.36' -H 'Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8' -H 'Referer: http://jwc.scu.edu.cn/jwc/frontPage.action' -H 'Cookie: FSSBBIl1UgzbN7N80S=QNhaD_Li_zNtT_cpiPFct4xmeeTANxTGFibJ1cr8UG5.TQTgf92kNGumIMQLJk7S; FSSBBIl1UgzbN7N80T=1bRmUMd.6dM5p8TpXQJvI1urtKs66zBfwsR4U8IUKJM3DPqrgH9mCyd8a0o6ENf1HhE6zJXgjgnSZu5bY738MYR6H4zHkB6kdfEbInL4XZwSql7GO0oi2PdMvJXIEGcXcPXtENRsCwd807oiG0NsxOnOXRW5VrI44QRhOuryY4_bXGKccPhMJBtaOUC2u0_ic70jvDX8rI7f16IcR4KvzPyxBdxY9iMWD5T4xtpDweG9TWiM7uonokdA9b30H1hbc93a70hygqnlvr_g3JMENxPyQ79pOTaLOSj__t4l87TbfTRCRm8R4VhycmdOLwjseVKALt1JgefXsn2zlPLg2S.Fl' -H 'Connection: keep-alive' -H 'AlexaToolbar-ALX_NS_PH: AlexaToolbar/alx-4.0.1' --compressed
但是直接curl jwc.scu.edu.cn -L是只返回一堆混淆之后的js
忽然明白,遇到反爬虫了
教务处为了我们技术进步也是煞费苦心啊(可能是爬教务处的人太多了扛不住了吧) 我用了条件get他也不理我,这个可不能怪我啦
混淆的js大概是这个样子
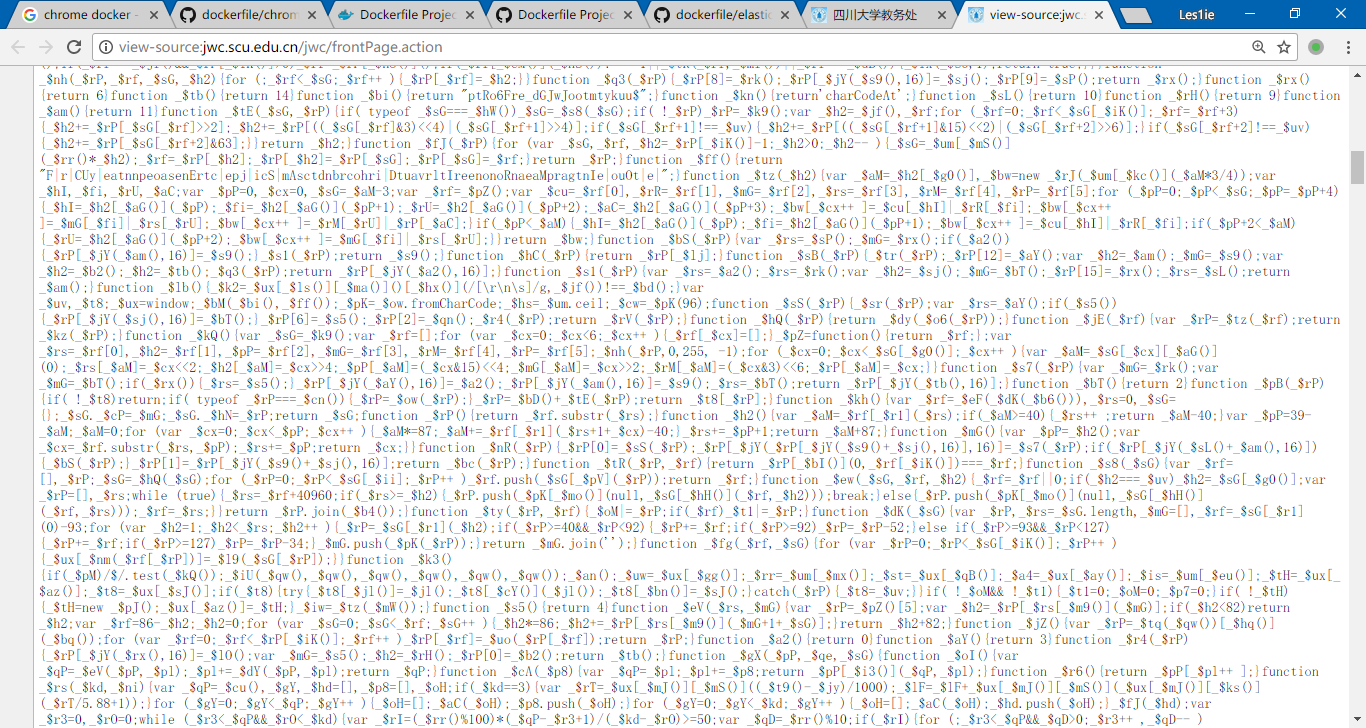
研究了下,教务处不按常理出牌,只认cookie, 不会去管refer和User-Agent,cookie里面有jsessionid, 大概一分钟过期,混淆的js是不想去分析的。
反反爬虫
看着这些js一个头两个大,自然想到了用requests的作者刚刚出的requests-html了,本机测试了下,报字符集错误,搜了下按照作者的解决方法也并没有解决,教务处也是utf-8的,莫非是我cmd的锅? 于是到服务器上去试了试,
突然注意到文档最后的一行字

debian的服务器是python3.5, 装pyenv吧..
pyenv装好了,改了.zshrc, 环境变量一直不生效,不懂为何,决定拖一个python 3.6.4的镜像下来试试,几经周折配置好了requests-html之后,发现报同样的错误,这时候可能需要甩锅给requests-html了,看来这个是走不通了,那么换一个方法
headless
以前是用的phantomjs爬一些特殊的网页,用起来没啥问题,但是最近多次听说chrome出了超高性能的headless版本,自然是想试下啦
网页的样式是没改的,所以原来的解析网页的代码可以继续使用的,这里只需要使用headless把网页源代码拿到就ok
改了几行代码,windows上把chromedriver.exe丢到同一目录下就ok, windows上面已经可以正常运行,headless总共半个小时就搞定了,感觉灰常舒服,如此轻松就干掉了教务处的anti spider 甚至想调戏一下教务处管理员,于是改了下ua..

好了提交gitlab,服务器拖下来准备重新部署
然后我才知道这一切只是个开始,我还是naive了,真正的大坑还在后面
项目是部署在docker里面的,需要给容器装上chrome然后把chromedriver放进去
就是上面这句话,花了我两天都没搞定
手动去下载了chrome linux版本,找到了可以使用wget直接下载的地址
1
https://dl.google.com/linux/direct/google-chrome-stable_current_amd64.deb
准备让docker build过程中去下载,学校是有ipv6的,直接下载是没问题,但是考虑到可能会到没有ipv6的地方跑,还是决定手动下载下来挂载进去
本来的想法:
1
2
3
COPY chrome.deb /tmp/chrome.deb
RUN dpkg -i chrome.deb
RUN apt install -f
在容器里面手动实现的上面的命令,发现容器会异常退出,试过几次也不知道为什么,于是决定直接在服务器上装试试
服务器上装倒是装好了,但是不知道装好了运行时啥子样子的呀

这个问题丢到了docker的群和python的群询问一番,发现没有人用过linux server + python + selenium + chrome headless + docker
突然想到firefox似乎也有headless呀,而且firefox对linux远远比chrome友好
自己电脑上又为firefox写了程序适配,搞定之后开始在服务器上装firefox,事实证明我还是太naive了,官方仓库只有esr版本,装stable版本和装chrome并无两样,(写这篇部落格的时候忽然想起来似乎并不需要deb只需要解压移动位置即可,解决依赖比chrome似乎简单)
遂放弃了使用firefox的念头
回归phantomjs
算了,还是用最原始的phantomjs吧,虽然去年这东西就停止更新了,然而本着能用的原则,再写了几行代码适配了phantomjs,运行的时候发现selenium已经弃用

并且用phantomjs不能过反爬虫验证,拿不到想要的源码,chrome和firefox都能过。
开始怀疑phantomjs没有等到页面加载完了就返回,于是加入了显示等待,但是没有用。
网上也找到了一些说明phantomjs和其他headless不一样的地方。
测试了其他网站,基本表现一致,但是教务处就不行,遂放弃phantomjs方案
当时在python群里面问了下这个奇怪的现象,某大腿说可以通过一些特定的返回值可以知道你是哪一种headless… 找到了一篇博客就是检测chrome的headless的, hacker news上面也看到有讨论(如果教务处管理员看到了这里不妨试试,这样技术才能互相进步嘛 :smiley:
再次回到chrome
又找到了selenium提供的chrome, 基于他的镜像去构建,但是还是有问题,现在想想可能是当时忘记加argument了….头晕了吧
到了晚上,决定再次手动装chrome测试一下
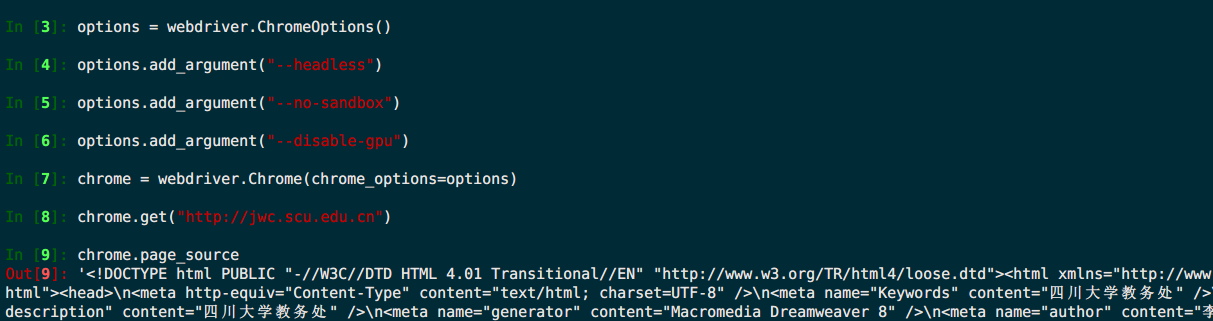 突然发现搞定啦 :man_shrugging:
突然发现搞定啦 :man_shrugging:
接下来就需要在docker中装好这个chrome了
docker build 会看RUN命令的返回值的,如果返回非0值,则认为执行出错,但是dpkg -i 安装chrome会报错的,所以需要手动解决这个问题,多次尝试,找到依赖包,提前下载
1
2
3
RUN apt update &&\
apt install libappindicator1 libasound2 libatk-bridge2.0-0 libatk1.0 libcups2 libdbus-1-3 \
libnss3 libx11-xcb1 lsb-release xdg-utils libgtk-3-0 libnspr4 -y
镜像终于搞定, chrome成功装好
再次放弃chrome,拥抱firefox
事先下载好了chrome的deb和chrome driver,放在项目的bin目录里面,感觉十分不爽,并且构建镜像需要好几分钟,虽然流程走通了,但是非常不情愿自己装chrome, 于是再度决定用selenium/standalone-chrome, 这个是基于ubuntu 16.04的,写好了dockerfile基于他去构建,不止为何有一个步骤出奇的慢,有一个120M的layer下载不下来,重试很多次都是一样的,虽然我是使用的dao.io的registry 加速镜像下载,但是似乎并没有作用,另一台服务器是用的ustc的registry, 但是实在不想去碰生产环境了,于是决定换成firefox。
简单修改了一下Dockerfile, 忽然发现程序并不能运行,说是wait-for-it不能运行python,搜了一下没有人有相似的问题啊..然后手动去镜像里面运行下,发现里面只有python3, 并且环境变量里面并没有python, 只有python3,于是改了一下docker-compose的command, 我以为这下搞定了, 可是并没有完..
再次运行,python的熟悉的ascii码的报错,但是我是python3了怎么还有错,终端的锅?网上搜了下,确实是这个问题,于是再开一个镜像试试,发现locale并没有设定中文支持中文的字符集,于是在dockerfile里面添加了一句
1
ENV LANG C.UTF-8
再次构建,成功了。
接下来就把可以运行的程序放到生产服务器去,程序终于又像以前一样欢快地运行了。
跋
教务处此次升级可能是存了很久的bug了放一起升级的吧,教务处之前校历的那里有乱码,现在去看已经修好了。
然后可能是教务处一直有类似我这样的不管服务端的暴力爬虫去爬,可能扛不住了,所以做了这个反爬虫的措施。
本来使用headless很简单的,我折腾了这么久的原因如下:
- docker里面装chrome有点麻烦,之前找过gist上面的脚本,但因为某些众所周知的原因并不能直接下载chrome的deb
- phantomjs这里不能工作了,原因不明,可能是他的反爬虫是针对phantomjs的?有时间了用工具反混淆试试看下他的js到底做了什么
- 感觉这个爬虫工具挺好用的呀,接收通知比较方便,所以在QQ空间给同学们推荐了一发,三个小时后看数据库发现增加了4个用户,翻了一番
- 后台看请求记录的时候才注意到, ua里面除了说明手机型号,平台之外,还说明了网络类型

Les1ie
2018年3月19日23:25:24