序
2017年暑假的时候经常逛freebuf,每天都会刷好几次
因为懒得打开,于是用了ifttt, 连接了pocket, 手机上有pocket的客户端,设定规则是 if freebuf更新文章了,then 添加到我的pocket阅读列表里面。
最初还有点用,但是后来渐渐发现这样用有点问题,不是随时有时间看,但是他的更新会一直加,加上当时订阅了好几个网站的更新,所以很快pocket列表也被堵满了,然后就关掉了这个channel
于是想自己写个freebuf的爬虫,有更新了就推送到我的邮箱,反正qq邮箱也不差几个辣鸡邮件
几十行代码就能搞定的,但是写的时候idea不断增加,想做一个通用一点的,然而事情比较多,没写完就搁gitlab仓库,再也没更新过了
于是2017年9月份,开学了,软件工程老师让我们做一个web相关的应用,于是 SCURSS便应运而生
最初的想法是, 爬教务处,学工部,结果放数据库,间隔一段时间再爬,如果有更新的了,那么推送到邮箱
但是这只会是一个自己用的小工具,那么怎么把它推广一下呢?
提供订阅机制,用户提交自己的邮箱,再告诉系统自己关心什么网站的更新,那么程序就对应地推送更新到邮箱
想了想,又准备给网站增加 RSS源的功能,感兴趣的用户可以订阅网站的RSS,就可以避免邮箱里面的更新的轰炸了..
嗯,后来发现周围的人除了我没几个知道什么是RSS的,不过这个功能还是要加的,毕竟我就是产品经理
问题又来了,用户怎么告诉我们他们对哪些网站感兴趣呢?
那么我们做一个web界面吧,用户可以在web里面把感兴趣的网站提交给我们
好了,思路就是这样,这些功能串行度不是很高,只要爬虫写好了,那么先做网站还是先给用户推送邮件都无关紧要了,毕竟预期用户是自己和其他的小组成员(逃
软工不能白学了,那么就用增量模型吧,xmind画了一下,然后就有了这个
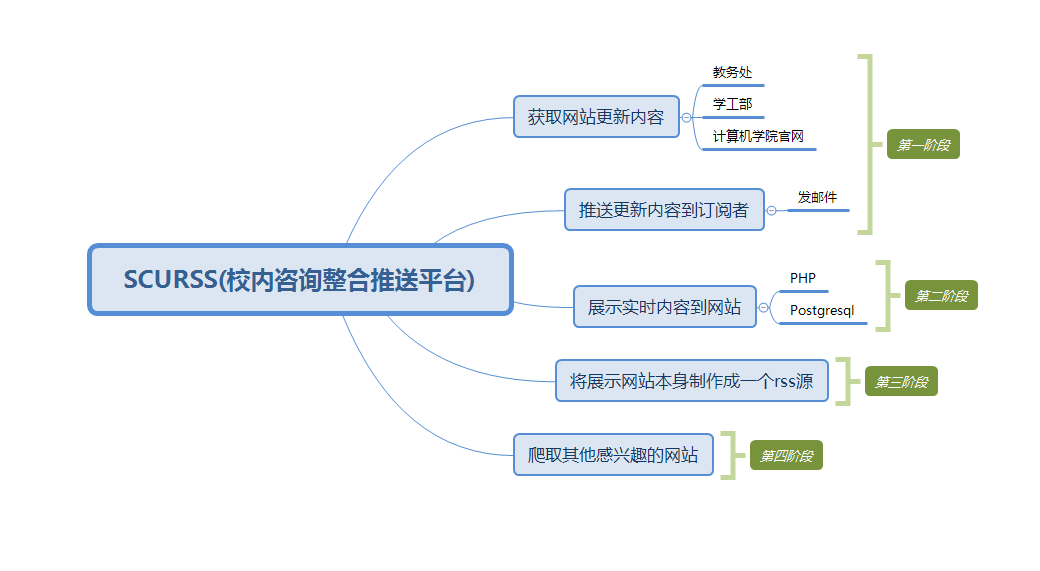
每个阶段一个增量
问题又来了,我们是三个人的小组,其中一个同学勇敢的承担起了网站的任务,那么我就只需要写爬虫和邮件推送了,还有一个生成rss的脚本
怎么协作呢? 想起以前几个人团队协作的时候是面对面 Ctrl + C, Ctrl + V 就觉得心惊胆战,哪里知道有没有冲突啊。
反正这次是两个人写代码,那么用git来协作吧,然后帮队友配置了git, ssh key,gitlab建了个group把他拉进来了,然后开始工作了
SCURSS 总体介绍
整个项目分为几个模块,然后分别部署到了5个docker容器中,
 其中
其中manage_python是主程序所在的容器,scurss_web是php的容器,init_mail_server是用flask写的一个api, pgsqldb是系统数据库的容器, mail_redis是redis容器,缓存当前注册的用用户
爬虫队列
因为要爬好几个网站,所以每个网站都要写对应的代码我是拒绝的,网上找了下 scrapy爬取多个网站, emmmmm…看了下太麻烦了还不如自己搞, 所以还是自己手写的,但是这些网站我要获取的内容是相同的,那么写一个基类吧,取个名字spider/Spider.py, 其他的爬虫就继承他
没几行代码,没用多线程,没用异步,炒鸡原始的方式,获取首页的内容需要加上进入每一条新闻把他的新闻内容抓出来,一般情况下只需要0.5 秒,所以很不优雅的写法也够用了
试了试加一个if-modified-since头,但是教务处根本不理我,还是返回所有的东西,所以…每隔两个小时就对教务处发动一次小型的dos不能全部怪我啦
在根目录下下有一个manage.py去引入了所有的包,所以每一个爬虫程序只需要返回一个包含每条新闻的字典组成的列表就行了。
插入数据库
数据拿回来了,怎么放到数据库里面呢,设计了一个简单的表来存放,之前想用mongodb,因为想存json进去,后来发现很多地方都在说postgresql炒鸡好用,而且支持json,然后就用了,当时也考虑到mysql的文档更多,遇到了问题也方便查资料
然后pgsql遇到问题的时候到处查资料的时候发现mysql 5.7支持json了…
不过还是用了postgres把这个项目搞定了,并且并没有用json存数据
还是mysql的文档多,支持广
第一次连接数据库的时候,如果数据库不存在,会报错,找了下,发现可以不指定数据库进行连接,这样可以先查看数据库是否存在,不存在就新建,然后再去连数据库。
项目写完了发现,其实建立docker镜像的时候就可以传环境变量,这样可以省去create_db()函数,而且如果不写这个只针对pgsql的函数的话,可以更方便迁移到其他数据库。
create_table函数是每次运行整个项目都进行一次检查,因为这是部署在docker中的,docker可以很经常的完整重建环境或者迁移环境,那么要做好兼容性,无论任何时候,冷启动还是热启动都能正常运行,所以做了这个处理。
内容发生更新修改的消息 and 新公布的消息
查数据出来,算哈希,不一样的就是更新的,不存在的就是新出来的新闻,关键函数如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
def check_update(self):
"""
:return: json list 包含所有的有更新的网站的原始内容
不提供网站修改的前后的变化
"""
cur = self.conn.cursor()
# 获取所有新闻的id
sql = """
select newsid from {}""".format(self.table)
cur.execute(sql)
all_newsid = [item[0] for item in cur.fetchall()]
# 做set的交操作,获取所有存在的新闻的id
exist_id = set(all_newsid) & set([news['id'] for news in self.info])
# 提取出新出来的新闻的列表
for news in self.info:
# 不存在set里面说明是新公布的
if news['id'] not in exist_id:
self.new.append(news)
print("新公布的新闻id ", news['id'])
else:
# 存在更新内容的
sql = """
select newscontent from {} where newsid='{}'""".format(self.table, news['id'])
cur.execute(sql)
content = cur.fetchall()[0][0]
if hashlib.md5(content.encode('utf-8')).hexdigest() != hashlib.md5(news['content'].encode('utf-8')).hexdigest():
self.update.append(news)
print('更新了以前的新闻的内容的id ', news['id'])
# 插入数据库的时候需要注意,最后更新全部消息的爬虫更新时间
return self.new, self.update
检查每隔新闻是否更新的时候代码改了很多次,做了多次优化,最初是遍历每一个新闻,去数据库中看这个newid字段是否存在,那么复杂度是O(n^2),而且数据库读是一个io操作,虽然是内网环境,但是还是有影响,所以一次性查出来数据库中所有的newid,放到一个列表中,然后遍历的时候就直接看列表中是否存在,此时的复杂度是O(n),而且去掉了重复的连接数据库。下一步的优化是把数据库查询到的记录和当前爬取到的新闻的id做一个集合的与操作,存在的就是已经有的新闻,复杂度变成了O(1),但是这个时候还需要检查每一条新闻是否更新,如果读出来全部的新闻的内容放到内存就不怎么合适了,空间换时间现在有点不划算了,所以这个地方最后 的复杂度还是O(n)。
数据库中有一个字段是记录上一次爬行整个网站的时间,这个方便检查程序是否正常工作,每一次完整的爬虫完成以后并且执行了数据的更新操作之后,会修改这个字段
推送消息到用户
发邮件,这个简单,不用多说
网站显示当前数据库的内容
这个由php实现
对于每一个版块,分别查一次数据库,然后放到网页中对应的位置即可。
用户提交信息后发送欢迎消息
因为前端现学用php发送邮件有点不现实,比较费时间,所以自然想到了我用python再写一个邮件发送的,或者复用之前写好的代码也可行。
那么如果web有用户注册,那么就docker内调用api,代码的最后几行使用file_get_contents() 来触发api,然后flask会进行邮件推送的操作。
flask会给用户发送欢迎邮件。怎么得知是哪个用户注册了呢?最简单的做法是在用户数据表里面加个字段表示是否已经发送了欢迎邮件了,如果发送了就置1,刚注册的时候置0,但是我又不想对postgresql有过多的写,因为这个api是前端调用的,可能会被攻击,导致频繁触发,那么… 我用了一个redis 缓存已经注册了的用户,api被触发的时候去pg里面取出来所有的用户,二者相比较就可以知道谁新注册的了,当然这是一个很不科学的写法,纯粹为了方便
问题来了,如果用户提交了好几次自己的邮箱怎么办呢?
那么用最新的吧,而且需要保证用户的邮箱是可用的格式,前端h5做的验证肯定是不可靠的,php后台也没做验证,直接插入了,那么首先每个邮箱最新的记录,然后正则验证一下,然后用set去重。
1
2
3
4
5
6
7
8
mail_pool = {item[0] for item in userinfo}
vilid_mail = []
for mail in userinfo:
if mail[0] in mail_pool:
vilid_mail.append(mail)
mail_pool.remove(mail[0])
else:
continue
比对一下就知道是哪些用户新注册了
那么怎么比较呢,用户可能是新注册的,那么肯定有个新的邮箱出现,但是如果用户只是用以前的邮箱注册了,更换了下订阅的节点呢,想了很久,想了个办法
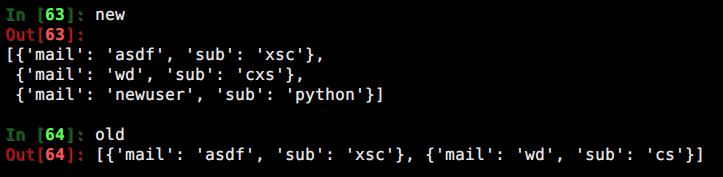
然后用

感觉非常不pythonic, 请教了一些大神,他们也没好的建议,因为里面的字典是不可哈希的,比较烦
然后突然发现有个炒鸡简单的方式
1
2
3
4
if redis_mail_info:
new_user = [item for item in userlist if item not in redis_mail_info]
else:
new_user = userlist
我是zz
生成 feed.xml
最简单的一个模块,网上搜了下,得知有几个模块可以生成rss, 最后选择了 pyrss2gen
其中有一个很坑的地方,生成的xml文件,头部的申明是ISO-8599-1,这个是拉丁语的字符集,表达中文肯定是有问题的,用chrome打开是乱码,但是在linux的终端里面打印是正常的,觉得非常纳闷,不知道怎么弄成utf-8然后看这个的文档也没说怎么说明xml文件的格式,然后网上搜了快一两个小时了,试过好多方法,都不行,然后问了下孔壕,他过来看了下,让我把头部的申明直接改成utf-8,说实话我是拒绝的,觉得没软用
然后可以了..
甩锅chrome?
chrome是按照xml头部的申明来解析这个xml文件的,头部的申明是iso-8599-1,自然就按照这个格式去解析,那么肯定出问题了,但是我Ctrl + U查看源代码了,他也按照了这个去解析? 从结果来看,是这样的。
那么每次生成了这个文件我都手动改一遍吧申明头吧,怎么改呢?
解析xml再改了再写回?
no no no
读取文件,字符串替换,写回, 搞定。
问题解决。
跋
-
瀑布流模型是一个很有用的东西,仅限于学生写作业的时候
-
增量模型可能好用一点
-
xmind 挺好用,免费版都这么舒服了,要是有个专业版岂不是上天
-
docker真好用, 加上docker-compose 编排容器,简直美滋滋,搭环境外加运行程序只需一条命令(孔壕说的三条),非要装b的话我觉得就是一条嘛
1
$ git clone xxxx && cd xxx && docker-compose up -d
-
redis 真好用,默认情况下没密码倒是挺方便别人进去玩的
-
postgresql 可还行,在我只对他写了几条单表查询的语句的时候说的,复杂环境我可不知道了
-
列表解析,集合操作,简直方便,想了很久都不能解决的问题,最后一句列表解析搞定。二十行还嵌套好几层的
for都搞不定的,一行列表解析也能搞定 -
容器内的访问速度真快,最初调试的时候我把服务器映射到了公网,所以每次访问web都会先去美国,再到学校,然后学校内的php再去美国,再回来去他同一个宿主机内的隔壁的一个docker里面取出来每个站点的消息,去到的消息送到美国再回到php容器里面,拼凑出html之后再送到美国,然后拿给用户浏览器,开一个网页要绕地球四圈。 上线之后把所有的地址都改成了容器互联,关掉了
6379的外网访问,然后端口映射到公网,这样每次打开只需要绕地球一圈了,当然如果用内网ip只会走1km的路程就拿到hmtl了 -
手写的php,开发没安全意识的话,就算只有十行代码也会被sql注入,那些ctf的web题并不全部是为了出题而故意构造的漏洞
-
如果说requests 是http for humans, 那么arrow 是datetime for humans
-
开发的头比较冷
2017年12月14日15:30:58